Methodology
Data Sources
American Community Survey
Most district statistics come from the American Community Survey (ACS). The ACS is a large, high-quality nationwide survey conducted by the U.S. Census Bureau. In 2024, the ACS response rate exceeded 80%, and the total sample included nearly 2 million households.
ACS 5-Year Estimates
We use the ACS’s 2024 5-Year Estimates, which draw from surveys conducted from 2020 through 2024. The 2024 5-Year Estimates are the latest 5-year data available; the 2025 5-Year Estimates should be available in early 2027.
Ideally, we would use more recent data rather than aggregating five years of survey responses, some of which are several years old by the time the estimates are released. However, only 5-year estimates have a large enough sample to compute statistics at the local district level.1 On the city homepages, the four summary cards use ACS 1-year estimates instead, since citywide sample sizes are large enough to support the more current release.
CDC PLACES
Statistics on health conditions come from the U.S. Centers for Disease Control and Prevention’s PLACES data. The CDC PLACES data come from a combination of the Behavioral Risk Factor Surveillance System Survey (BRFSS) and the American Community Survey (ACS). The BRFSS surveys over 400,000 people every year on a range of health topics. While it is a large survey, it is not large enough to estimate health statistics at a hyperlocal level. To produce reliable local estimates, the CDC combines BRFSS and ACS data using a technique called multilevel regression and poststratification modeling.
For each census tract, ACS data describe the demographic composition of the local population, including residents’ age, sex, race and ethnicity, and educational attainment. BRFSS data are then used to estimate how the prevalence of different health conditions varies across those demographic groups. Multilevel regression and poststratification combine these two sources by applying BRFSS-based health estimates to the demographic profile of each tract. Essentially, the prevalence of various health conditions in a tract is predicted based on the tract’s demographic characteristics from the ACS.
The CDC PLACES data were last published in 2025 and are based mostly on data from the 2023 BRFSS survey and the 2019–2023 ACS. Five measures are based on 2022 BRFSS survey data: 1) Colorectal cancer screening, 2) Mammography, 3) Short sleep duration, 4) Dental visit, and 5) All teeth lost. CDC PLACES data is updated annually.
Unlike the survey-based estimates elsewhere on this site, CDC PLACES values are modeled estimates, and the CDC does not publish a margin of error for them. We therefore do not show a margin of error for any CDC PLACES measure. One measure, the share of adults who have lost all their teeth, is only asked of adults 65 and over; we express it as a share of all adults 18 and over so it is comparable to the other measures, which are reported for all adults 18 and over.
Census Local Air Conditioning Estimates
Estimates of air conditioning access come from the U.S. Census Bureau’s Local Air Conditioning Estimates (LACE). These estimates come from combining local data from the American Community Survey with national data on air conditioning access from the American Housing Survey (AHS), also administered by the Census Bureau.
The American Housing Survey does not have a large enough sample to provide estimates of air conditioning access at a hyperlocal level. To produce reliable local estimates, the Census combines AHS and ACS data similarly to how the CDC combines BRFSS and ACS data. In this context, the Census used individual survey responses from the ACS rather than ACS data aggregated to the tract level. Thus, rather than predicting tract-level outcomes from an area’s demographics, the model predicts AC access for each household based on that household’s characteristics, then aggregates the predicted AC access to the tract level using an approach called cross-survey modeling.
The Census Bureau’s local air conditioning estimates were released in 2026 but refer to data collected in 2023. Since these estimates are new, it is not yet clear how often the Census will update them.
Census Community Resilience Estimates for Heat
Estimates of community resilience to heat come from the U.S. Census Bureau’s Community Resilience Estimates (CRE) for Heat dataset. The data is designed to show a community’s vulnerability to extreme heat by defining and tabulating the average number of social vulnerability measures present in the community. The vulnerability measures come directly from the American Community Survey. Unlike the Local Air Conditioning Estimates and CDC PLACES data, the CRE for Heat data does not rely on cross-survey modeling. The specific social vulnerability measure definitions are described in detail on our social vulnerability definitions page.
The Census Bureau’s Community Resilience Estimates for Heat data was published in 2024 and refer to data collected in 2022. Historically, the data has been updated every three years.
Geographic Aggregation
Plain-English Summary
Local district statistics are generally not precomputed by the Census Bureau or other statistical agencies. It is also not possible to simply aggregate survey responses from people within a given district from census data: the Census Bureau does not reveal respondents’ precise geographic locations. To calculate local district statistics, we aggregate data from smaller geographic areas that fall within or overlap a given district, using the most granular geographic information the statistical agency releases. Some of these areas do not perfectly align with district boundaries: part of the area may be inside the district, while another part is outside of it. When this occurs, we weight the data by the fraction of the area’s population that falls within the district boundaries. While this geographic mismatch is unavoidable, validation tests suggest that it has a very small impact on the accuracy of district statistics. For the subset of metrics where we can test the effect of imperfect boundary overlap, average errors are less than half of one percentage point.
Aggregating Across Census Geographies
Local district statistics are not precomputed by the Census Bureau. To calculate them, we take a weighted average of smaller geographic units, called census tracts, that fall within or overlap a district. For readability, the examples below refer to census tracts, but the actual calculations use the smallest available geography for each measure: block groups when block-group data is available, and tracts otherwise.
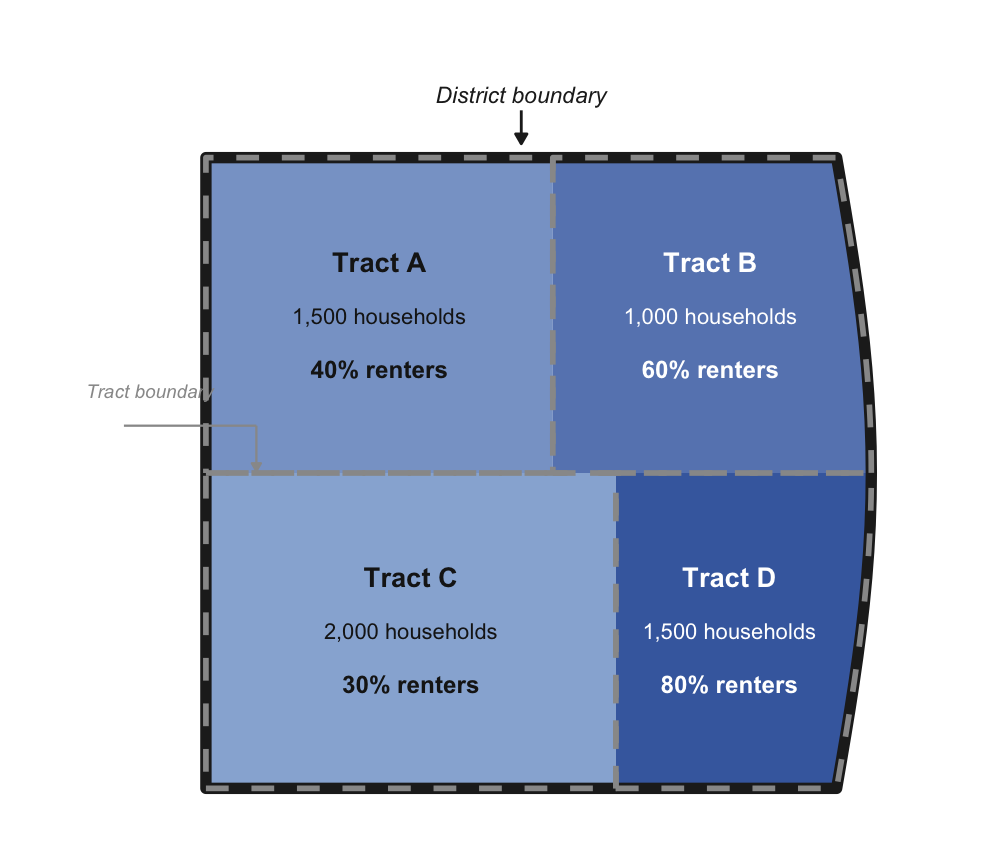
As a simple example, consider calculating the percentage of renter-occupied households in a district with four census tracts, each of which is fully within the district boundary:
To find the district-level renter percentage, we take the weighted average of the tracts’ renter share, weighting each tract by its total number of households:
District renter % = (popA × renter%A) + (popB × renter%B) + (popC × renter%C) + (popD × renter%D) popA + popB + popC + popD
= (1,500 × 40%) + (1,000 × 60%) + (2,000 × 30%) + (1,500 × 80%) 1,500 + 1,000 + 2,000 + 1,500 = 50.0%
Dealing with Imperfect Overlap Between Tracts and Districts
In practice, census tract boundaries do not always align with district boundaries: some tracts include residents from multiple districts. For split tracts, we use the data for the full tract, including residents living both inside and outside the district boundary. We account for the fact that some residents live outside the district by weighting the tract by the fraction of its population falling within the district boundaries, rather than using the tract’s total population.
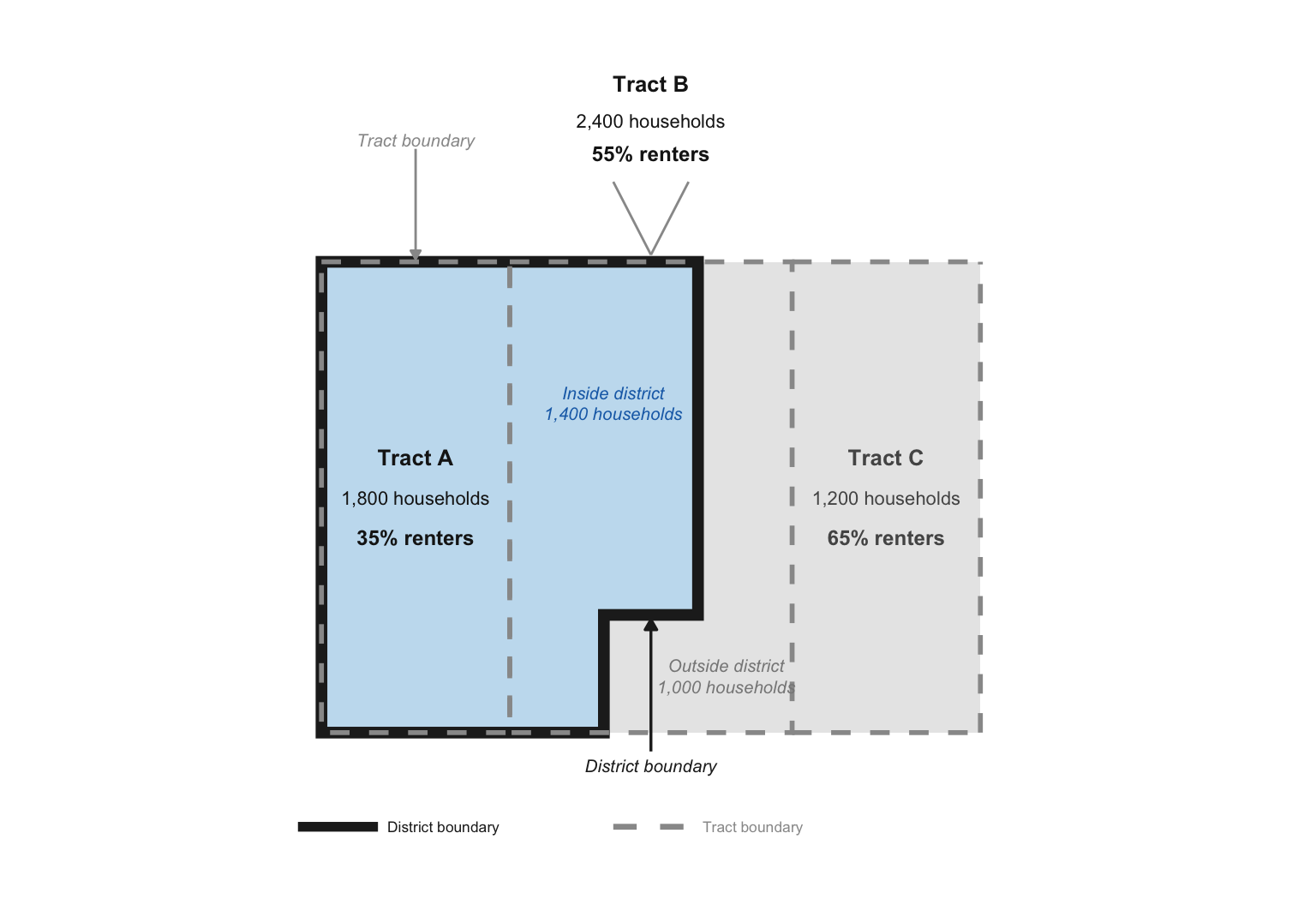
For example, the figure above shows a district boundary that fully encompasses Tract A but only partially overlaps Tract B. When calculating the district’s renter share, we know that 35% of households in Tract A are renter-occupied and that 55% of households in Tract B are renter-occupied, but we do not know the renter share for the portion of Tract B inside the district. However, we do know how much of Tract B’s population is inside versus outside the district. We account for this by weighting Tract B’s renter share by the population of Tract B inside the district, 1,400 households, rather than by its full population, 2,400 households.
District renter % = (popA × renter%A) + (popB, in district × renter%B) popA + popB, in district
= (1,800 × 35%) + (1,400 × 55%) 1,800 + 1,400 = 43.8%
We calculate the share of each split census tract’s population within the district using block-level data from the 2020 decennial Census. Census blocks are very small and almost always fall entirely within a single district.2 The figure below shows how block-level population data can be used to weight split tracts, using the example from Tract B above.
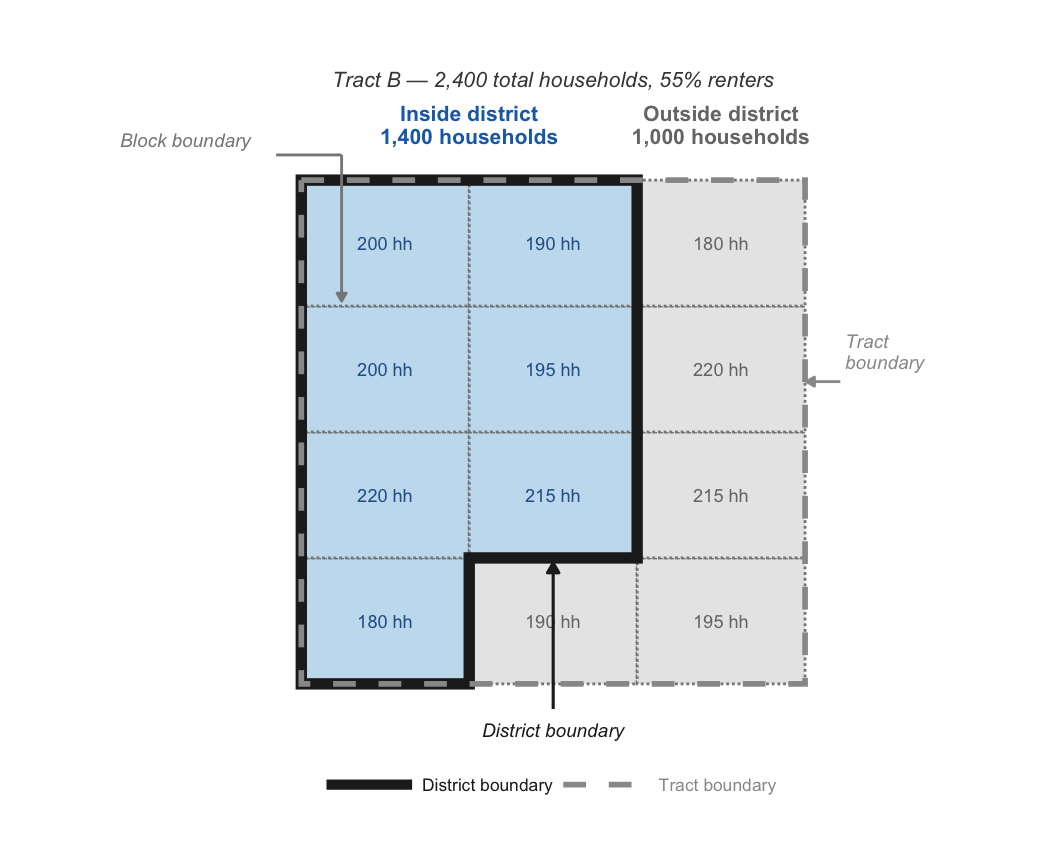
Importantly, only a handful of basic variables, such as population and housing-unit counts, are available at the block level. While we have total population data at the block level from the 2020 decennial Census, renter share and most other ACS variables are available only at higher levels of aggregation. As a result, we must use the tract-wide renter percentage rather than the renter percentage for the portion of the tract within the district boundary.
Sources of Error and Imprecision
Sampling Error
The ACS surveys a sample of households rather than every household in the country. Because the ACS captures only a slice of the population, any statistic it produces is an estimate — and like all estimates, it comes with some uncertainty. If the ACS were conducted again with a new sample of households, it would yield slightly different results. This sample-to-sample variation is called sampling error, and it exists for all surveys.
A survey’s margin of error quantifies the uncertainty from sampling error. It defines a range around the published estimate within which the true population value is likely to fall. For example, if a district has an estimated renter-occupied household share of 42%, with a margin of error of ±4 percentage points, the true value is likely between 38% and 46%.3 ACS margins of error are reported at the 90% confidence level, meaning that if the survey were repeated many times, the true value would fall within that range about 90% of the time. Each district page has a button that allows users to toggle margins of error on or off for each estimate. Technical details on how we compute district-level margins of error from ACS tract and block group data are described on this page.
Geographic Aggregation Error
When a tract overlaps a district boundary, our calculations necessarily incorporate some data from people living outside the district. This introduces geographic aggregation error — a source of imprecision distinct from sampling error. Unlike sampling error, geographic aggregation error is not directly quantifiable from the published ACS data.4 The degree to which a district is mismeasured by incorporating non-district residents depends on how different those non-district residents are from district residents, which is unknown.5
While we cannot directly test geographic aggregation error in the ACS estimates, we can test it using block-level decennial Census data. Since Census blocks are very small, we can use them to produce district-level estimates without geographic aggregation error. Using the same data, we can compute district-level estimates with geographic aggregation error by applying the same methodology we use on the ACS data.6 Comparing district estimates from block-level data aligned directly to district boundaries with estimates produced using our tract- and block-group aggregation method allows us to quantify how much imperfect geographic overlap between Census and district boundaries can skew estimates.
For each district, we show the geographic mismatch between Census boundaries and district boundaries, as well as validation tests using decennial Census data with and without geographic aggregation error. Importantly, decennial Census data is available for only a small number of measures, including race, age, owner- versus renter-occupied households, and household types.7 However, geographic aggregation error in measures included in the decennial Census may differ from the error in other ACS measures. For instance, the portion of a split tract inside the district may have a similar renter share to the portion outside the district, a measure available in both ACS and decennial Census data, while rent prices may differ substantially across the same boundary, a measure available only in the ACS.
Self-Report Errors
ACS data come from self-reported responses, which are subject to error. The degree to which this matters varies by question. For instance, most people can accurately report their age, but when asked the year their building was constructed, respondents may give their best estimate rather than a precise answer. More broadly, the accuracy of survey data depends on the reliability of self-reported responses. For questions like building age, answers should be understood as rough approximations rather than precise measurements. We try to account for this in how we present the data. For instance, our housing age variable uses wide bins that convey the rough age distribution of the housing stock, such as relatively new, middle-aged, and older buildings, rather than precise construction dates.
Median and Percentile Calculations Are Approximations
When calculating medians and percentiles, such as median household income and 25th percentile home values, we average tract-level values within a district rather than computing them directly across the full district, which is not possible from published ACS data. Averaging tract-level medians and percentiles is an approximation of the true district-wide values. To calculate the true median or percentiles, we would need either a Census geography that directly matched district boundaries or the underlying microdata with address-level geographic identifiers. This simplification will increase the influence of extreme values. For instance, if one tract within a district has a very high median income, averaging across tracts gives that high-income tract more influence than it would have if the median were computed directly. As a result, the reported median income would be higher than the district’s true median income.
Footnotes
The Census does not release precise geographic information from the American Community Survey to protect the privacy of respondents. To calculate district-level statistics, we have to aggregate data across the geographies that the Census Bureau does release. The smallest published geographic units typically include only 1,200 to 8,000 people, and there are not enough survey respondents within those units in a single year. The 5-year estimates combine five years of survey responses to provide more stable and reliable estimates for smaller geographies.↩︎
In the rare cases where a block straddles a district boundary, we weight the block’s population by the share of the block’s area falling within the district.↩︎
Not all values within this range are equally plausible. The published estimate is the single most likely value; plausibility decreases gradually toward the edges of the range, following a bell-curve distribution.↩︎
Arguably, sampling error also has some unquantifiable bias. Traditional margins of error are calculated based on an assumption of a random sample. In practice, not everyone who receives the ACS answers the survey, and people who respond may differ from people who do not respond. This breaks the logic of random sampling that margins of error are based on and makes the degree of total sampling error also fundamentally unknowable. However, the ACS is a very high-quality survey, with high response rates and methods designed to reduce sampling bias.↩︎
Population shifts within split tracts since the 2020 Census (which is the data source we use to weight split tracts by the fraction of the population inside the district) may also be a source of error.↩︎
Specifically, we aggregate data from Census blocks up to the tract and block-group levels, then use those data the same way we use ACS data: weighting units that split district boundaries by their block-level population.↩︎
The ACS is far more comprehensive and surveys people more frequently than once every 10 years, which is why we use it despite the presence of geographic aggregation error.↩︎